Week 1
Reading papers summary
A Relational Model of Data for Large Shared Data Banks
[!Abstract] Several operating system services are examined with a view toward their applicability to support of database management functions. These services include buffer pool management; the file system; scheduling, process management, and interprocess communication; and consistency control.
Buffer Pool Management
Fundamentals
- In an OS like UNIX, a buffer pool of fixed size is set upon compiling the OS code.
- File reads are handled through this cache
- the relevant data is fetched from a cache block if the block exists
- otherwise, a block in cache is evicted and replaced by the relevant block from disk
- UNIX uses LRU eviction policy
- Sequential access to the same file could trigger prefetching of the block in the future
Performance
Inherent costs that make up overhead include:
- system calls
- address space context switching
- core-to-core latency when data is passed between CPU cores
[!Note] Optimization via user space Some databases, e.g. INGRES and System R, places the managed buffer pool in user space to avoid the cost of context switching.
LRU Replacement
In INGRES, there are typically 4 types of access patterns:
- sequential access to blocks which will not be rereferenced
- sequential access to blocks which will be cyclically rereferenced
- random access to blocks which will not be referenced again
- random access to blocks for which there is a nonzero probability of rereference.
For cases 1 and 3, where we know exactly some blocks that will never be referenced again, we evict them immediately after reading them. For case 4, LRU makes sense.
Prefetch
The main drawback of prefetch is random access of cache blocks. When reading a block, suppose we know what the next N blocks that will be needed are. Those blocks may not be the next ones in the logical file order from current seek.
Crash Recovery
Many DBMSs have an intentions list of tasks. This just serves as a transaction log but associated with a trigger for committing. Once all tasks for some specific transaction have been added to the intentions list, then a commit flag is set to true. Upon a system crash, recovery checks whether this flag has been set. If so, the intentions list is run to update the database state. Otherwise, no action.
Textbook notes
Chapter 1
Definitions
database-management system (DBMS) - a tool, literally an extensive program, that aggregates and organizes related sets of data for storage and retrieval
database - collection of data containing information relevant to an enterprise
The primary goal of a DBMS is to provide a way to store and retrieve database in a convenient and efficient manner. A DBMS has to manage over data that are described as:
- highly valuable
- relatively large
- are accessed by multiple users and applications, including simultaneously
The functionalities offered by DBMS rely heavily on abstraction.
[!Note] Abstraction Abstraction allows someone to use a complex device or system without requiring specific knowledge on the details of how that device or system operates under the hood.
Two modes under which databases run under:
- OLTP - support online transaction processing
- many users use the database, each retrieving relatively limited number of records and/or performing small updates
- primary mode of use for most users
- OLAP - support data analytics i.e. processing of data to infer conclusions and form decisions, often needed to drive business decisions
Purpose of database systems
A DBMS utilizes a file-processing system under the hood. This is a typical file system run by conventional OSes like Windows or Linux. However, there are some disadvantages of relying on such file-processing systems.
- data redundancy and inconsistency
- same field, such as someone’s name, may be duplicated across multiple files
- various copies of the same data may no longer agree i.e. see the same changes from initial creation of the file
- difficulty in accessing data
- to search for some field that satisfy a specific criteria, such as users with an address in a specific geographical area, would require full scans of all files containing name and address regardless of the actual number of relevant records
- data isolation
- data is scattered across different files, which may be in different formats,
- integrity problems
- data values stored in the database must satisfy certain types of consistency constraints, such as a user’s age cannot be negative
- atomicity problems
- files can be prone to leave breadcrumbs of partial updated fields during a crash
- concurrent-access anomalies
- two or more users making modifications to the same field without restricting access at specific time points can corrupt the data
- example, a bank account with $1000 with withdraw requests for $10 and $20 may be non-deterministic, as the remaining balance could be either $990 or $980 depending on which write was completed last
- security problems
- only specific users may be allowed to make modifications or read a certain file
- sometimes, rwx file permissions may not be enough for more complex permission management schemes
View of data
Data models
-
relational model - collection of tables to represent both data and the relationships among those data. This is typically what most database systems use to store data structurally.
-
entity-relationship (ER) model - collection of basic objects, called entities, and relationships among these objects. Analogous to relations between classes/structs in a software program, represented by some UML diagram.
-
semi-structured data model - each data item, even of the same type, may contain independent set of attributes. Furthermore, the whole model is often a hierarchy of nested data items. XML and HTML are common examples.
-
object-based data model - same concept of objects in object-oriented programming (OOP) languages like Java and C#. Standards exist to store objects in relational tables in modern database systems.
Data abstraction models
From lowest to highest level, these data abstraction models are:
- physical level
- how the data are actually stored
- low-level data structures needed to handle files and data units
- e.g. B+ tree for relational table, i-nodes for the physical files on disk
- logical level
- what data are stored in the database and the relationships among those data
- view level
- exactly what it sounds like, this provides a partial view of a database
- example, out of N columns in a relation for users, suppose you only need contact information for a user (name, email, phone_number)
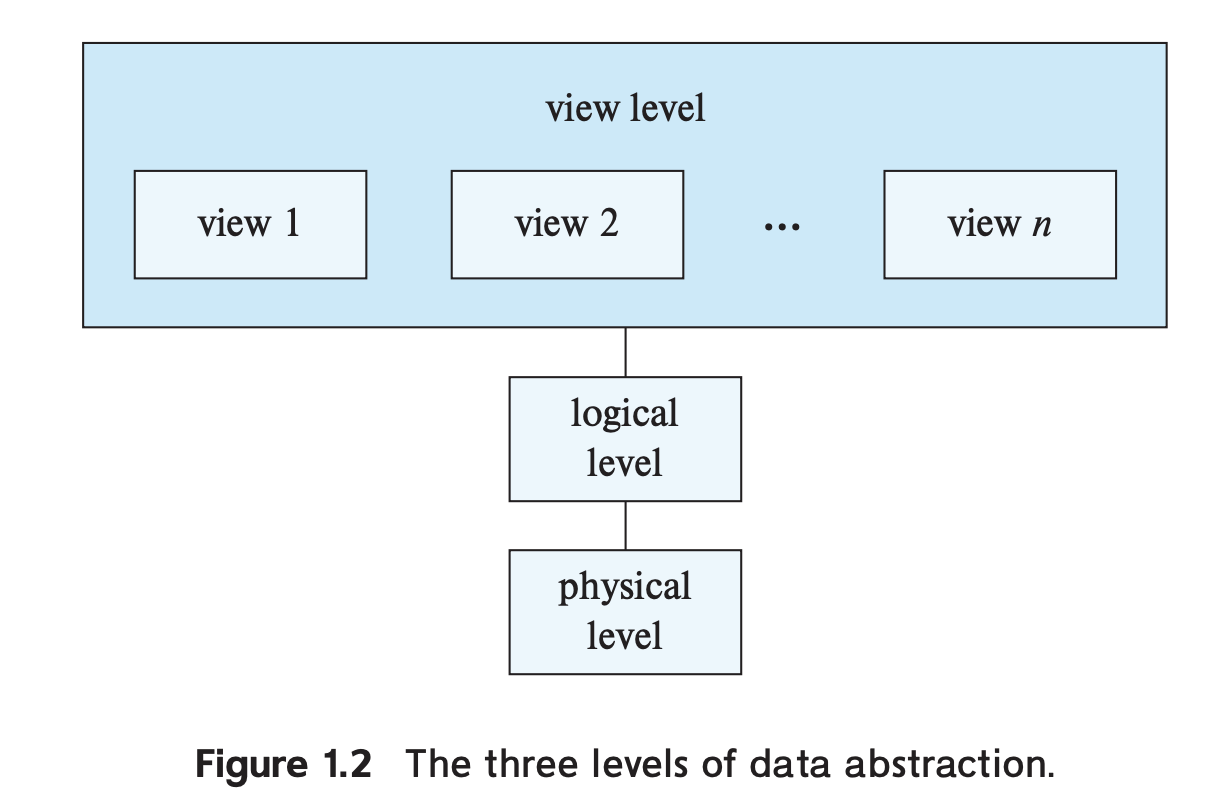
Instances and schemas
The variables in a program at any time point is an instance of a database schema. Think of schema as equivalent to a class definition in an OOP language.
Database systems have unique schemas, one for each level of abstraction. There is usually one physical schema and one logical schema, while several schemas at the view level may exist. Those describe different views of the database and are sometimes called subschemas.
Database languages
Data-definition language (DDL)
This is a special language used to write the database schema. Furthermore, a special type of DDL i.e. a data storage and definition language help define the implementation details of the database schemas, usually hidden from users.
A schema written out by DDL can and often should define constraints on the relation. From a general sense, constraints can be classified by the following categories.
- domain constraints - the actual set of possible values for fields inside a schema
- referential integrity - enforcement of relationships between schemas i.e. the existence of a field in one relation implies the existence of another field in a different relation
- authorization - differentiate among the users on the access type each user is permitted on a relation. The authorization can be as fine-grained as having an individual permission (or lack of) for each action under CRUD.
After executing a DDL script, the output is stored in the data dictionary. This is an auxiliary table containing metadata that only the DBMS can access internally. The DBMS consults with the data dictionary before reading or modifying actual data.
Data-manipulation language (DML)
This language allows users to specify which data they want to access or modify in context of a specific data model. There are four standard actions a user can take (CRUD).
C - insertion of new information into the database R - retrieval of information stored in the database U - modification of information stored D - deletion of information from the database
There are two types of data-manipulation language:
- procedural DML
- require the user to specify which data are needed and how to fetch it
- declarative DML a.k.a. nonprocedural DMLs
- require a user to specify what data are needed without needing to say how to fetch
- SQL falls under this type
Database design
Database design mainly involves the design of the database schema. The design of a complete database application environment that meets the needs of the enterprise being modeled requires attention to a broader set of issues.
Designing a data model typically goes through several stages in sequence.
- conceptual-design phase
- detailed overview of the enterprise
- confirm all data requirements have been satisfied without conflicting with one another
- focus on describing the data and their relationships
- design is often guided by a specification of functional requirements
- specifies the kinds of operations i.e. transactions allowed on the data
- logical-design phase
- maps high-level schema onto the implemented data model
- physical-design phase
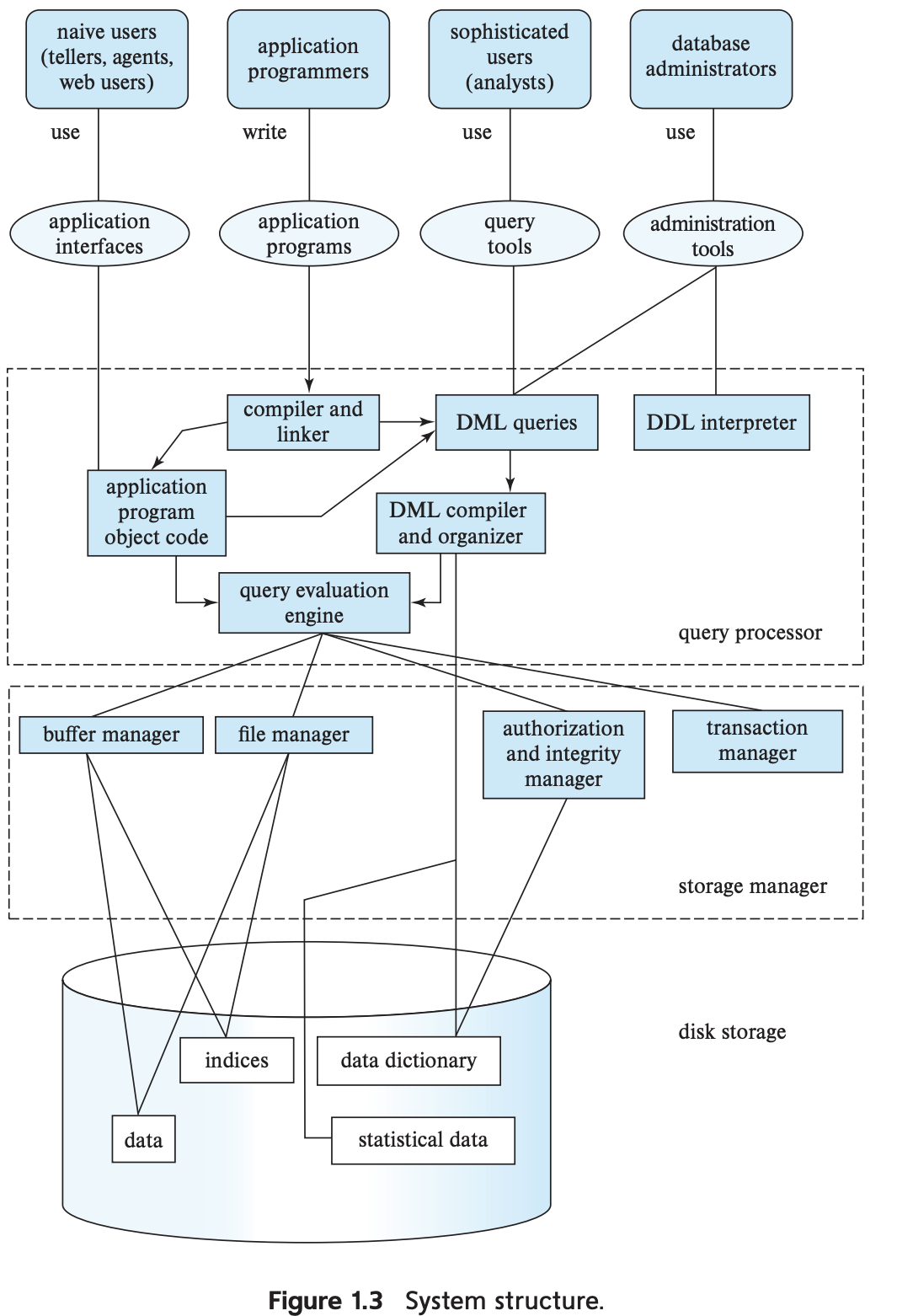
[!Note] The functional components of DBMS can be organized into
(1) storage manager (2) query processor components (3) transaction management.
Storage manager
This is the middle man that interfaces between low-level data i.e. raw files and the application programs and queries submitted to DBMS. Components of the SM include:
- authorization and integrity manager - tests integrity constraints and checks authority of users demanding access to data
- transaction manager - ensures database remains in a consistent state even through system failures, and that concurrent transaction executions proceed without issue
- file manager - manages allocation of disk space along with the data structures used to represent on-disk data
- buffer manager - responsible for fetching data from disk storage into main memory, and deciding what data to cache in main memory
- enables the database to handle data much larger than main memory capacity
Query processor
The query processor has the following components:
- DDL interpreter - interprets DDL statements and records definitions in data dictionary
- DML compiler - translates DML statements into an evaluation plan written in low-level instructions that are then passed to the query-evaluation engine
- one query can usually be translated into one of several semantically equivalent evaluation plans that all yield the same response
- performs query optimization amongst those evaluation plans
- query evaluation engine - executes low-level instructions generated by DML compiler
Transaction management
This is all about complying with ACID properties from the DBMS.An important component to transaction management is the recovery manager. It is actually a group of two sub-components, listed below.
- recovery manager
Suppose there is a system crash on one of the nodes with an ongoing transaction. To uphold atomicity, a failed transaction must have no effect on the state of the database. The recovery manager restores the state of data from before the interrupted transaction started executing.
- concurrency-control manager
Within a multithreading context, concurrency-control manager ensures the consistency of the database when multiple threads attempt to complete transactions.
Database and application architecture